
While studying LLMs, one often encounters the term RAG.
RAG stands for Retrieval-Augmented Generation, a process that optimizes the output of large language models by referencing reliable information from outside the training data source before generating responses.
What was the problem?
As everyone knows, large language models like ChatGPT, Claude, and Gemini are trained using vast datasets, enabling them to perform a variety of tasks.
However, while learning general knowledge and generating answers probabilistically, the following problems arise.
1. Hallucination
One of the biggest issues is hallucination, which refers to the phenomenon where the model generates information that does not exist in the training data.
Recently, this problem has significantly decreased in models capable of inference, but models that generate answers probabilistically can hardly avoid it due to the nature of probability.
2. Providing Outdated Information
Since LLMs are trained on vast datasets, they inevitably include outdated information.
Especially in development, when explaining code using an extremely outdated version of a library or copying and pasting, it can lead to problems where one realizes that the function has already been deprecated.
3. Generating Responses from Unreliable Sources
Among the information available online are false or unreliable information uploaded by people, leading to occasional provision of information with unclear sources as the AI learns from this.
4. Absence of Accuracy Due to Term Confusion
Because LLMs learn from various training sources, multiple terms may be intermixed in responses, making users confused when the same concept is expressed using different terms.
Birth of RAG
Let’s Stuff References into Inputs
Initially, due to the problems mentioned above, attempts were made to resolve them by extremely increasing the input prompts.
For example, when generating responses about law, one might insert the entire legal code.
However, since the legal code must be referenced every time an input is made, this approach is very cost-inefficient and practically inconvenient.
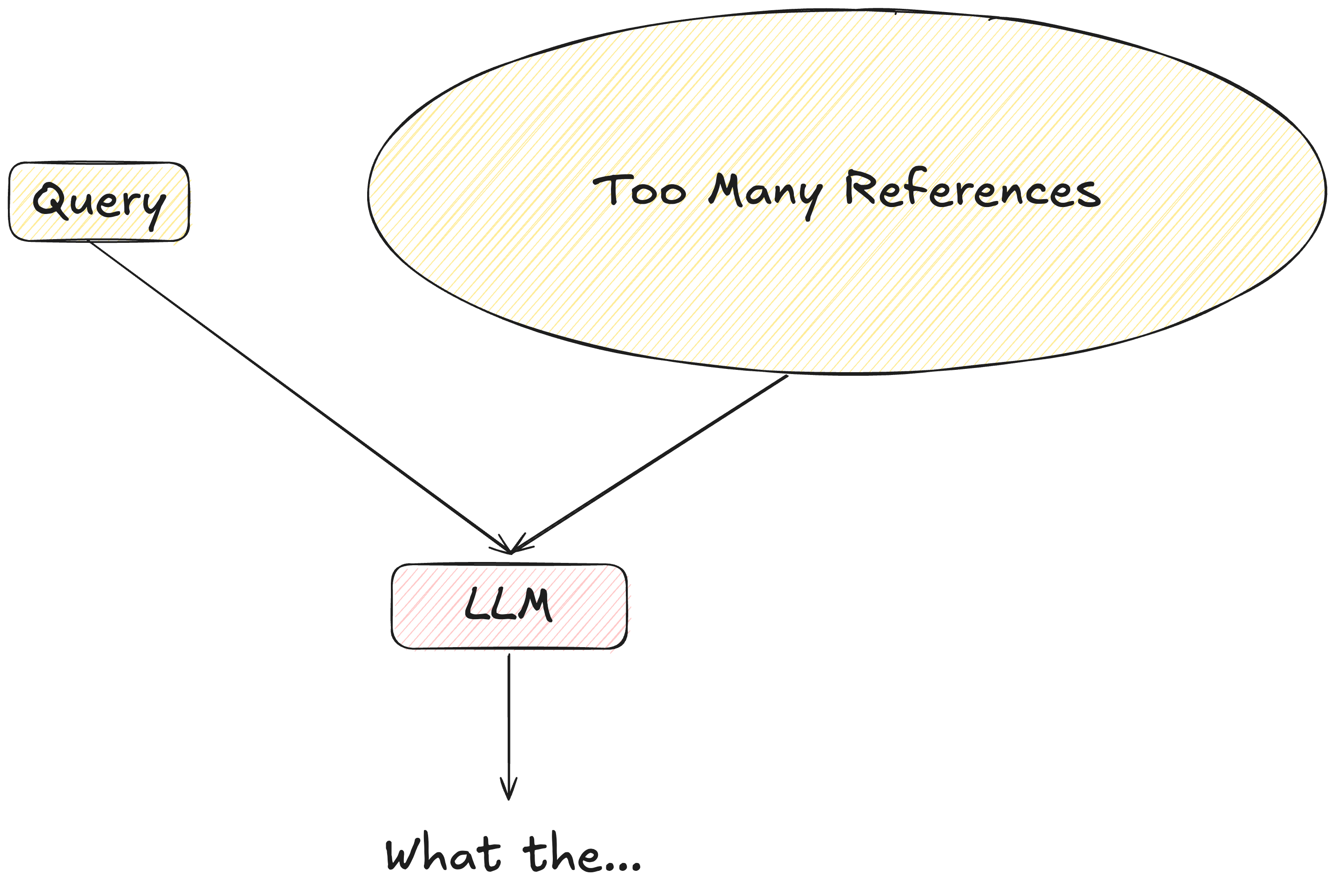
Moreover, given the characteristics of LLMs, if the input data is too vast, the hallucination problem may worsen.
Refer Only to Relevant Data: RAG
Thus, RAG proposes a method to refer only to relevant data among the input data to solve these issues.
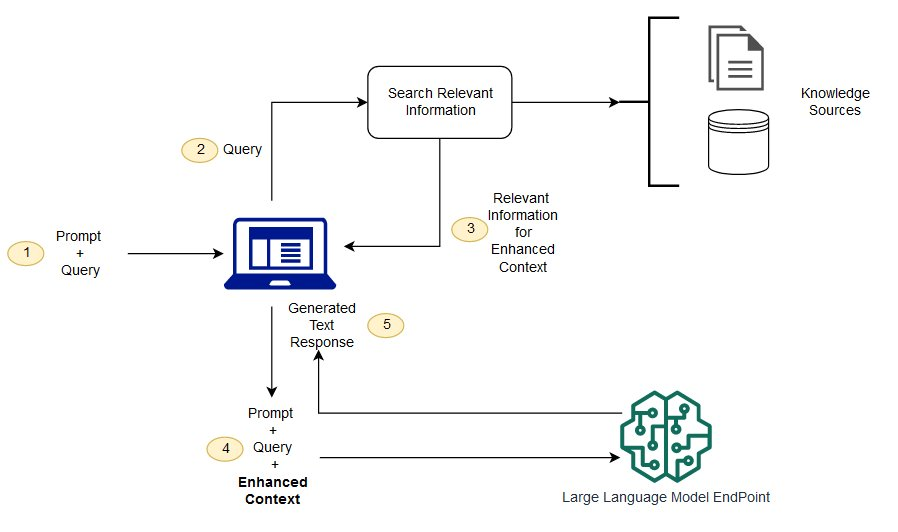
As shown in the diagram, RAG reduces hallucination by referencing only the relevant data and generates responses based on reliable information.
Too much context is eliminated through Retrieval, and responses are generated based on reliable and relevant contexts.
Among this, the “Search Relevant Information” pertains to currently commonly finding related information through vector search using embedding models.
Isn’t There a Search Engine for Searching?
Traditional search engines provide very fast search speeds through reverse indexing using tokenizers.
However, since searches can generally only be performed when keywords match exactly, it is not suitable for RAG, which needs to search using queries composed of prose.
For instance, if one searches with the following sentence:
Search about the doneness of steak
The search engine tokenizes it like this:
[스테이크, 익기, 정도, 검색]
Due to this tokenization, in an OR condition, documents may be retrieved that contain unrelated keywords like ‘정도’ and ‘검색’, and in an AND condition, only very few documents containing all keywords may be retrieved.
The information the user actually sought regarding the doneness of steak (e.g., well-done, rare, medium, etc.) may not be found.
This content follows the general algorithm of reverse indexing and tokenizer-based search engines. Nowadays, many search engines have started to support vector searches.
Embedding Models
Thus, RAG generally uses embedding models to convert sentences into vectors for searching.
While traditional search engines find documents based simply on the keyword ‘monkey’, the method using embedding models can search all documents related to monkeys, including ‘ape’, ‘chimpanzee’, etc.
Vectors are transformed numbers representing words, possessing a certain dimension.
Dimension
For example, the word ‘apple’ and ‘banana’ can be transformed into [0.5, 0.4] and [0.2, 0.1], respectively.
quadrantChart
Apple: [0.5, 0.4]
Banana: [0.2, 0.1]
This can be represented as shown above on a plane.
Based on these transformed vectors, a method is employed where similar cases are positioned closely together, and differing cases are placed further apart.
The higher the dimension, the more precise the search can be. For example, in a plane (2D), there exist only the x and y axes, but this can be expanded to 100 dimensions, 1000 dimensions, thus enabling more accurate searches.
Here, dimensions can encompass multiple criteria. For instance, whether the spelling is similar or whether the meanings are similar can be examples.
Naturally, the more dimensions there are, the more comprehensively one can judge word similarities.
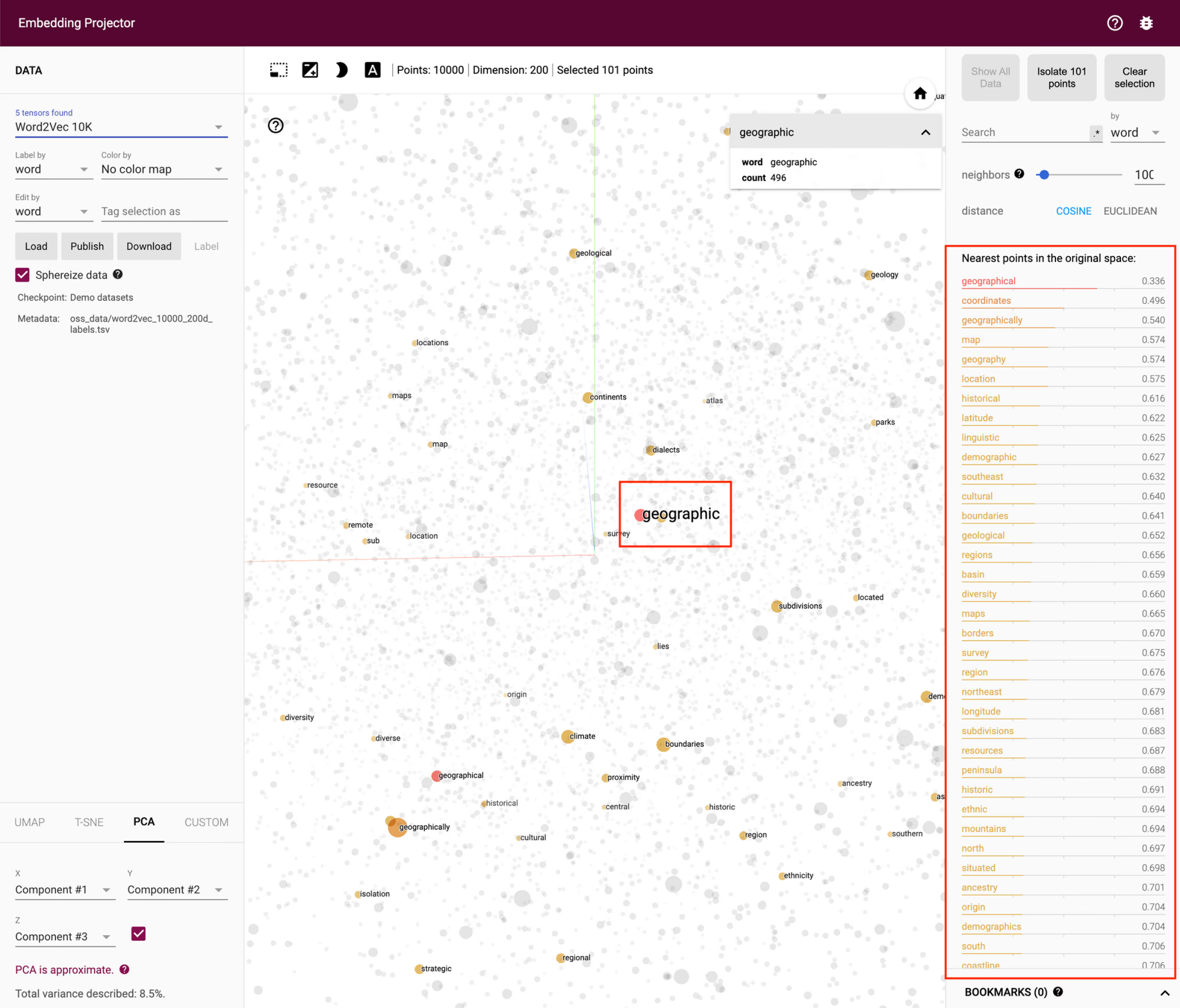
+ Curse of Dimensionality
The higher the dimension, the “curse of dimensionality” problem occurs.
That is, as dimensions increase, the density of the data decreases; for instance, visually comparing 100 data points displayed on a 2D plane to those on a 3D plane shows that the data on the 3D plane appears much sparser.
Thus, in such cases, techniques like PCA and T-SNE are used to reduce dimensions.
Recently, dimensionality has not been a major issue in embedding models. Considering that Google has announced a model with 3072 dimensions, it seems that this problem has been somewhat resolved.
Who Created It?
Upon reflection, to vectorize countless prose, an enormous amount of data relationship information is needed.
For instance, to semantically equate the Korean word ‘사과’ with the English ‘Apple’, data containing this information in advance is necessary.
There are thousands to millions of words in the world, and labeling their relationships is an impossible task for an ordinary company.
Companies capable of creating and providing models in a useful form include well-known names like Google and OpenAI.
They possess pre-combined AI models and offer them in an API format.
- Google Cloud - Overview of Embeddings API
- OpenAI - Vector embeddings
- NAVER - Embedding
- Voyage - Text embedding models
The actual use can be expressed in the following diagram.

Storing and Searching
If every search data is converted into vectors via the API each time, it would be highly inefficient, and the cost of using the Embedding API would also rise significantly.
To solve this problem, a method of converting and storing search data as vectors and utilizing vector operations is employed.
Nowadays, most well-known databases provide vector operation functionality.
(Refer: PostgreSQL, MySQL, MongoDB)
This can be represented in the following diagram.
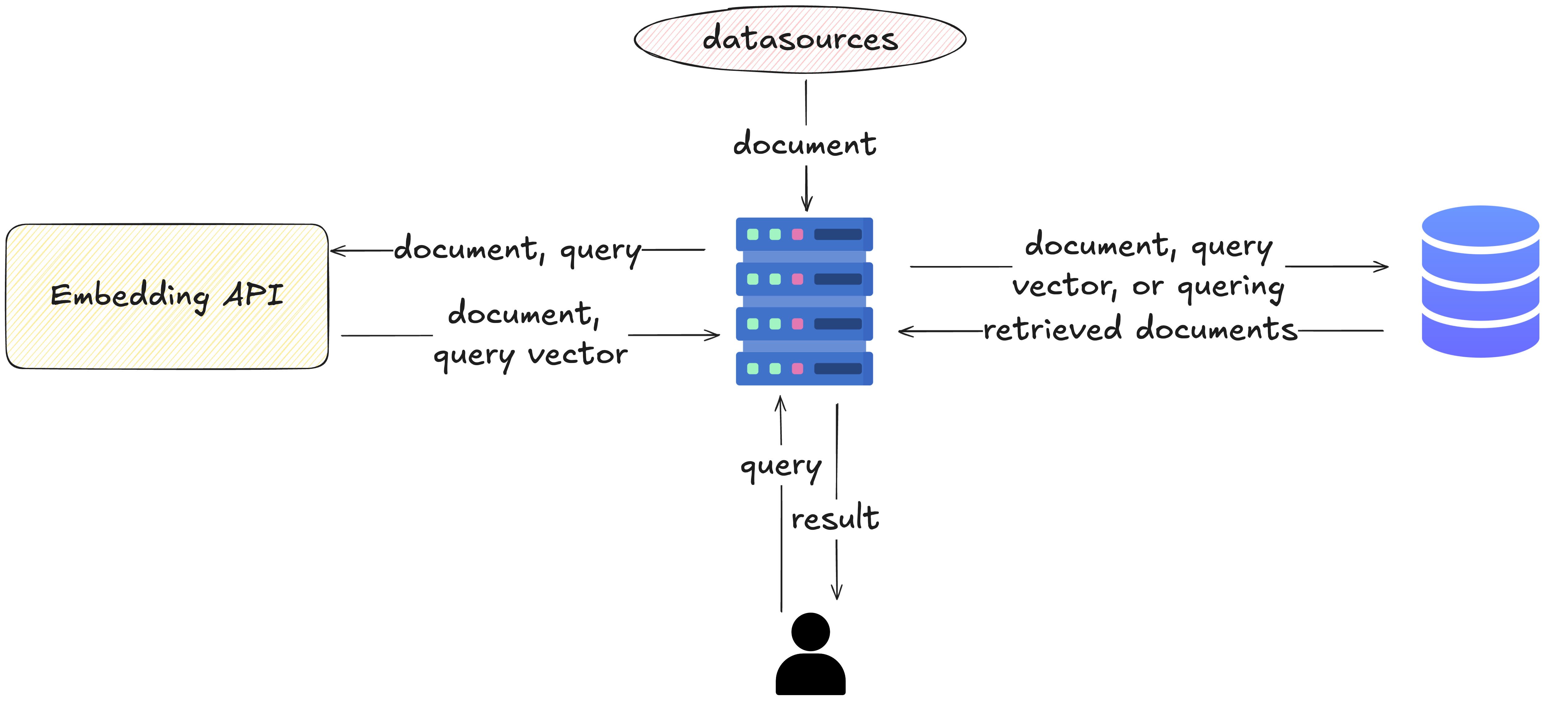
- Convert the data to be searched into vectors via the Embedding API.
- Store the transformed vectors in the DB.
- When a user queries, convert the query into a vector via the Embedding API.
- Compare the transformed vector with the vectors stored in the DB to find the most similar N vectors.
- Return the original data for the found vectors.
Vector operations generally use cosine similarity.
Cosine similarity measures similarity using the angle between two vectors.
Generally, the size of the vectors is not considered, as it does not affect similarity.
Conclusion
In the past, searching using search engines like Elastic Search was viewed as an incredible new technology, but currently, embedding models seem to replace traditional search engines.
If keyword matching is important, traditional search engines are worth considering, but the embedding models, which can perform not only keyword matching but also semantic inference, demonstrate significant potential in many areas.
In the next post, we will delve deeper into the implementation of RAG through example code using Google’s embedding model.
Reference
- https://aws.amazon.com/ko/what-is/retrieval-augmented-generation/
- https://the-dev.tistory.com/30
- https://www.syncly.kr/blog/what-is-embedding-and-how-to-use
- https://modulabs.co.kr/blog/%EC%B0%A8%EC%9B%90%EC%9D%98-%EC%A0%80%EC%A3%BC-curse-of-dimensionality
- https://docs.voyageai.com/reference/embeddings-api
- https://api.ncloud-docs.com/docs/clovastudio-embedding
- http://platform.openai.com/docs/guides/embeddings
- https://cloud.google.com/vertex-ai/generative-ai/docs/embeddings?hl=ko